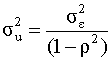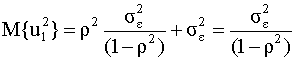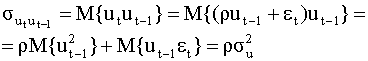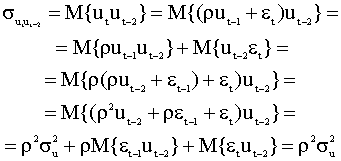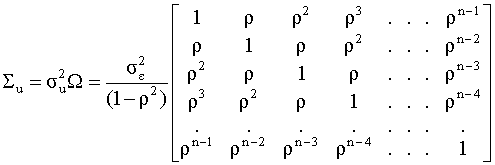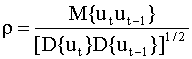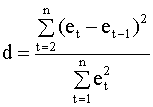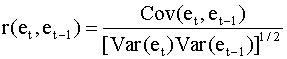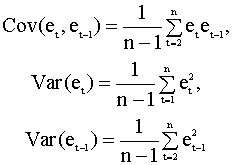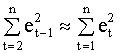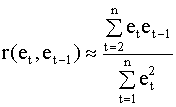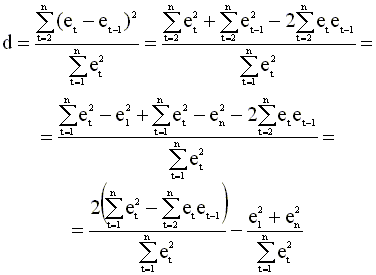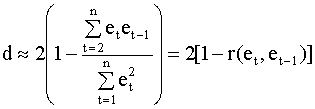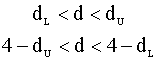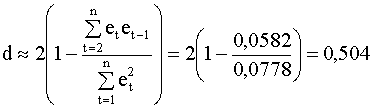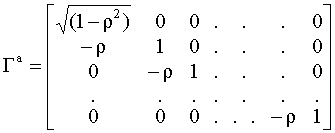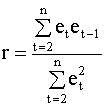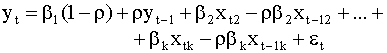|
4.4. Автокорреляция возмущений: определение, диагностика и процедуры устранения Рассмотрим линейную регрессию
где Xt=[xt1, xt2,...,xtk]T. Будем считать, что индекс t у переменных модели означает, что их значения (регрессанда и регрессоров) изменяются во времени: yt и xtp, - значения переменных в момент времени t (t=1,2,…,n, p=1,2,…,k) то есть модель строится не по пространственной выборке, а по временной, и, чтобы подчеркнуть это, при описании временных выборок мы используем индекс t. Таким образом, уравнение (4.29) описывает временной ряд зависимой переменной. Для оценки параметров модели временного ряда (4.29) в условиях предпосылок классической регрессии можно использовать обычный МНК. Однако при моделировании временных рядов часто возникает проблема автокорреляции возмущений. Суть ее заключается в том, что возмущение (случайная составляющая) модели ut в момент времени t зависит от возмущений в предыдущие моменты наблюдений. Автокоррелированность возмущений можно учесть с помощью так называемых моделей авторегрессии. Простейшей из таких моделей является модель авторегрессионного процесса первого порядка (процесс авторегрессии первого порядка). Такой процесс описывается следующим уравнением
где Рассмотрим некоторые
простейшие свойства процесса
авторегрессии. Применяя к обеим
частям уравнения (4.30) операцию
математического ожидания и учитывая,
что для начального значения
Таким образом, как следует из полученного выражения (4.31), в общем случае дисперсия процесса авторегрессии зависит от времени (случайное возмущение гетероскедастично). Однако, если начальное значение u0 случайного члена имеет дисперсию
то и для любого t дисперсия случайного члена также равна
и не зависит от времени - случайная составляющая гомоскедастична. Покажем это. Для t = 1 с учетом (4.32), (4.31) имеем
Аналогично можно показать, что и для последующих t=2,3,…,n, выполнено соотношение (4.34), если при каждом t в качестве начального значения регрессии брать ее значение на предыдущем шаге ut-1 (здесь, по существу, используется простейшая схема доказательства по индукции). Определим элементы ковариационной матрицы вектора возмущений. Умножим левую и правую части уравнения (4.30) на ut-1 и к получившемуся выражению применим операцию математического ожидания. Получим
поскольку
В общем случае точно также можно показать, что Таким образом,
ковариационная матрица
Эта матрица отличается от
диагональной, поэтому для оценивания
модели с автокорреляцией возмущений
необходимо использовать обобщенный
метод наименьших квадратов. Очевидно,
что элементы матрицы
Выражение (4.36) совпадает с определением коэффициента корреляции. В социально-экономических исследованиях этот параметр должен быть оценен на основе эмпирических данных, после проведения теста на автокорреляцию. Замечание. Для моделирования авторегрессионной зависимости между наблюдениями можно использовать авторегрессионные процессы и более высоких порядков. Модели таких процессов будут рассмотрены в следующей главе, посвященной анализу временных рядов. Процедура тестирования на автокорреляцию: тест Дарбина - Уотсона Существует множество
различных тестов для диагностики
автокорреляции. Одим из наиболее
известных и достаточно просто
реализуемых на практике является тест
Дарбина-Уотсона (кратко - d -тест). С
помощью этого теста проверяется пара
гипотез: гипотеза При этом важно иметь ввиду что: 1). При нулевой гипотезе предполагается, что исследуемый процесс описывается классической моделью линейной регрессии, то есть выполнены все предпосылки классической модели (см. п. 3.1). 2). Тест не проверяет, действительно ли автокорреляция имеет вид авторегрессии первого порядка (а не описывается другими возможными формами автокорреляционных зависимостей), вид авторегрессионной зависимости постулируется, а проверяется только наличие или отсутствие автокорреляции первого порядка. Тест Дарбина - Уотсона основан на d - статистике (критерии) Дарбина-Уотсона, которая вычисляется по формуле
Здесь et - остатки регрессионного уравнения. Для их вычисления уравнение оценивается с помощью обычного метода наименьших квадратов. Можно установить зависимость между d - статистикой и выборочным коэффициентом корреляции между соседними ошибками et и et-1. Напомним, что выборочный коэффициент корреляции имеет вид
где выборочная ковариация и дисперсия равны
Для выборки достаточно большого размера можно записать приближенное соотношение
учитывая которое, выборочный коэффициент корреляции (4.38) можно представить так
Критерий (4.37) можно записать в виде
Последнее слагаемое в полученном выражении близко к нулю и им можно пренебречь (при достаточно большом n). Тогда окончательно (учитывая (4.39)) получаем
Содержательная интерпретация статистики Дарбина - Уотсона Опираясь на выражение (4.40), можно
дать следующую содержательную
интерпретацию статистики Дарбина-Уотсона.
Если между соседними ошибками модели
существует положительная корреляция Распределение d - статистики зависит от следующих величин: 1) от длины наблюдаемого ряда n; 2) от количества регрессоров k; 3) от конкретных наблюдаемых в данной реализации числовых значений регрессоров, то есть от матрицы X. Последнее обстоятельство делает невозможным прямое построение d - теста, так как для этого потребовалось бы при каждом его применении заново составлять таблицу критических значений d - критерия для соответствующей матрицы X. К счастью, оказалось (Дарбин и Уотсон это доказали), что существуют две границы, которые определяют области принятия или отклонения гипотез относительно автокорреляции и зависят только от n, k и уровня значимости, но не зависят от конкретных наблюдений регрессоров. Для этих границ можно рассчитать табличные значения. Недостатком d - теста является существование зоны неопределенности, при попадании в которую d - статистики невозможно принять однозначного решения. При применении d - теста можно руководствоваться следующим эвристическим правилом: если значение d - статистики близко к двум, то автокорреляция возмущений первого порядка несущественна; чем ближе значение d к нулю, тем больше положительная автокорреляция; чем ближе значение d к четырем, тем больше отрицательная автокорреляция. Порядок применения d - теста 1). Вычисляем значение d - статистики по формуле (4.40). 2). Определяем табличные значения нижней границы dL и верхней dU для заданного уровня значимости и конкретных n и k. 3). Принимаем решение в соответствии со следующими правилами: а).
если б).
если в).
если г). области неопределенности:
4). Интерпретируем результаты тестирования. Замечание. Следует помнить, что корректное применение d - теста требует выполнения предпосылки о некоррелированности регрессоров и возмущений модели. Поэтому его нельзя применять, если, например, в модели присутствуют лаговые (запаздывающие) значения регрессанда в качестве регрессоров (подобные модели часто используются для описания авторегрессионных временных рядов, см. гл. 5). Практическая рекомендация. Наличие зон неопределенности
существенно снижает эффективность
практического использования d -
теста. Ошибочное принятие гипотезы H0
приводит к существенному искажению
результатов и потере свойств оценок. В
тоже время, отклонение нулевой
гипотезы, хотя она и верна, приведет
лишь к необходимости проведения
незначительных дополнительных
вычислений, связанных с оценкой
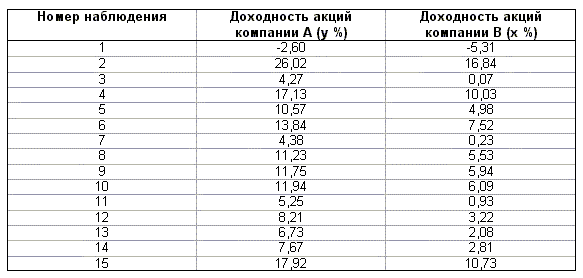
параметра авторегрессии Пример. 4.3. В таблице 4.2 приведены данные о годовых доходностях акций компаний A и B (источник: Л.О. Бабешко, 2001, с. 63, [4]). Используя данные таблицы 4.2 построим линейную регрессионную модель для изучения влияния изменения доходности акций компании - лидера B на доходность акций компании A и исследуем остатки полученной модели на автокорреляцию, применяя процедуру Дарбина - Уотсона. Спецификация модели имеет вид где yt - доходность акций компании A, xt - доходность акций компании B. Применение метода наименьших квадратов для оценки коэффициентов модели позволяет получить следующую эмпирическую функцию регрессии:
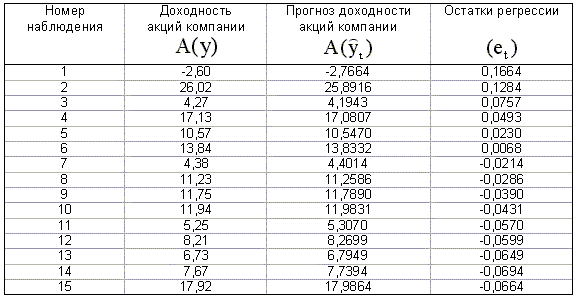
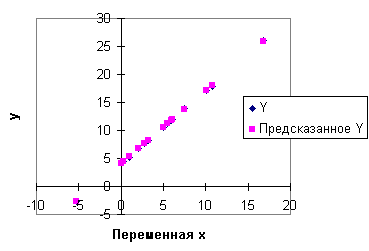
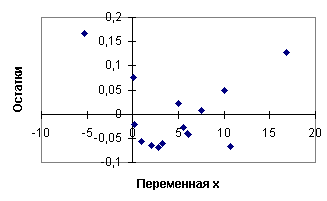
Прогноз значений зависимой переменной и вычисленные остатки регрессии приведены в таблице 4.3 На рис.4.13, 4.14 даны графики прогноза и остатков. Статистика Дарбина - Уотсона вычисляется по формуле (4.40):
Для количества наблюдений n
= 15, количества регрессоров k = 2 и
уровня значимости Задание. Определите для данной модели коэффициент детерминации, стандартные отклонения и доверительные интервалы для коэффициентов. Оценка авторегрессионного параметра и процедуры устранения автокорреляции Предположим сначала, что
значение параметра авторегрессии Учитывая уравнение авторегрессии (4.30), получим При t = 1 обе части
уравнения (4.29)
умножим на множитель Введем новые переменные:
Тогда уравнение преобразованной модели можно записать в виде
где вектор
В преобразованной модели (4.44)
возмущения удовлетворяют свойству
гомоскедастичности. Действительно,
компоненты вектора возмущений Замечание. При практической реализации описанного метода, для простоты часто ограничиваются только преобразованием вида (4.43), опуская первое наблюдение (4.42). К сожалению, при построении эконометрических моделей реальных социально-экономических процессов параметр авторегрессии, как правило, неизвестен и подлежит оцениванию. Существует множество различных процедур оценивания регрессионных моделей с одновременным оцениванием параметра авторегрессии возмущений. Рассмотрим некоторые из них. Итерационная процедура Кохрейна-Оркатта При подтверждении гипотезы о существовании автокорреляции первого порядка, процедура оценивания параметров регрессии с использованием преобразованной модели может быть проведена по следующей итерационной схеме. 1) Оцениваем обычным методом наименьших квадратов вектор коэффициентов исходной (не преобразованной) модели по формуле (3.15). Вычисляем вектор остатков e. 2)
Оцениваем авторегрессионный
параметр
Заметим, что данная оценка совпадает с выборочным коэффициентом корреляции (4.39). 3)
Строим преобразованную модель,
используя вместо параметра 4)
Вычисляем новый вектор остатков e = y
- Xb. Повторяем процедуру, начиная с
пункта 2). Итерационный процесс
заканчивается, когда два
последовательных значения оценок r
параметра Замечание. Для вычисления оценки r
можно использовать соотношение (4.40), из
которого получаем: Итерационная процедура Хилдрета-Лу 1)
Выбираем последовательно значения
коэффициента 2) Для
каждого значения Замечание. Данную процедуру можно
проводить в несколько этапов - сначала
определить "грубое" значение Преобразованную модель (4.44) можно записать в виде
К данной модели, очевидно,
можно применить обычный МНК,
рассматривая наблюдения yt-1
как регрессоры, а
|