|
Цель данной главы - изучение модели парной линейной регрессии. Глава содержит в основном традиционный материал - оценка параметров по методу наименьших квадратов, обсуждение предпосылок модели, свойства оценок, построение доверительных интервалов для параметров и проверка гипотез, критерии адекватности модели, изучение которого должно предшествовать изложению более сложных вопросов, связанных с построением моделей множественной регрессии. 2.1. Модель парной линейной регрессии. Примеры 2.1.1. Понятие регрессионной зависимости, виды зависимостей Как было отмечено в предыдущей главе, одной из типичных задач, которую часто приходится решать на практике, является установление и количественная оценка связи и влияния нескольких (или одной) независимых переменных на зависимую переменную. Для решения подобного рода проблем в эконометрике используются методы регрессионного анализа. В наиболее общей постановке задача заключается в следующем. Объект исследования представлен наблюдаемыми величинами y, x1, x2,...,xk . Предполагается, что между этими величинами существует объективная причинная связь, то есть на основе предварительного анализа объекта установлено, что наблюдаемая величина y зависит от наблюдаемых величин x1, x2,...,xk . Эту связь между зависимой переменной y и независимыми переменными x1, x2,...,xk в принципе можно представить в виде функциональной, в общем случае нелинейной, зависимости, определенной с точностью до параметров, то есть связь между переменными в регрессионных моделях в общем случае определяется выражением
где Функциональная зависимость вида (2.1) называется регрессионной, а уравнение (2.1) - регрессионным. Замечание относительно терминологии. В регрессионном анализе зависимую (объясняемую) переменную называют регрессанд, а независимые переменные - регрессорами. В эконометрике часто для этих переменных используют также термины эндогенная и экзогенные переменные. В зависимости от количества регрессоров регрессионные модели подразделяются на модели парной регрессии (одна независимая переменная) и модели множественной или многомерной регрессии (несколько независимых переменных). В зависимости от вида функциональной связи регрессионные модели делятся на линейные и нелинейные. 2.1.2. Предмет регрессионного анализа. Линейная регрессия, классы задач, решаемых с помощью моделей линейной регрессии В линейной регрессии зависимость наблюдаемой количественной переменной y от наблюдаемых переменных x может быть выражена в виде
Функция (2.2)
называется линейные
множественной (многомерной) линейной
регрессией. Она линейна как
относительно регрессоров x, так и
параметров Подчеркнем, что вид зависимости (в данном случае линейной) и количество независимых переменных определяются на основе тщательного изучения и анализа предметной области и имеющихся статистических данных. Предполагается, что имеются значения наблюдаемых величин y, x1, x2,...,xk , то есть по каждой из них имеется ряд данных. Для конкретных наблюдений переменных y и x уравнение (2.2) записывается следующим образом:
где индекс t означает
номер наблюдаемой переменной, t=1,2,...,n,
всего наблюдений n. Эти данные
могут представлять собой временные
ряды наблюдений объясняемой (зависимой)
и объясняющих (независимых)
переменных, характеризующих
поведение изучаемого процесса во
времени и тогда индекс t
обозначает моменты времени
наблюдений. Это могут быть
пространственные данные, которые
характеризуют различные объекты, но
относятся к одному и тому же моменту
или периоду времени и тогда индекс t
- номер наблюдаемого объекта. Заметим,
что время может входить в уравнение (2.3) и в
качестве независимой переменной.
Коэффициент Основная цель регрессионного анализа - теоретически обоснованные точечные и интервальные оценки параметров регрессионной модели на основе пространственных или временных наблюдений ее переменных, точечный и интервальный прогноз значений зависимой переменой (или ее математического ожидания) при некоторых фиксированных значениях независимых переменных. 2.1.3. Примеры линейной регрессионной зависимости между экономическими переменными В первой главе были приведены примеры практических задач, для решения которых можно применять методы регрессионного анализа. Возможно, наиболее впечатляющие примеры регрессионных моделей, позволивших получить фундаментальные теоретические результаты и широко применяющиеся на практике, связаны с анализом финансового рынка. Здесь мы опишем две известные линейные регрессионные модели, которые используются для оценки финансовых активов. Однофакторная рыночная модель оценки финансовых активов Наблюдения показывают, что доходность (эффективность) обыкновенной акции за некоторый период времени (например, месяц) связана с доходностью фондового рынка в целом. Данную взаимосвязь можно выразить в виде рыночной модели где Для измерения эффективности
рынка используют рыночные индексы,
которые определяются как взвешенные с
учетом капитала суммы эффективностей
акций ведущих корпораций. В
Соединенных Штатах это, например,
индекс Доу-Джонса, S&P 500 индекс - Standart
and Poor's 500 Stock Index, при расчете которого
учитываются акции пятисот крупнейших
корпораций, NYSE Composite Index, для
вычисления которого используются
курсы акций, зарегистрированных на
Нью - Йоркской фондовой бирже и др., в
России - индекс РТС. Если для каких -
либо акций коэффициент "бета"
меньше единицы, то такие акции
называют "оборонительными". Риск
вложений в них меньше, чем риск,
связанный с рыночным портфелем, они
менее чувствительны к рыночному риску.
Если коэффициент "бета" больше
единицы, то такие акции называются "агрессивными",
они предполагают больший, чем
рыночный портфель, риск, эти акции
более чувствительны к рыночному риску.
Таким образом, коэффициент Данная модель широко
используется на практике для анализа
финансовых рынков. В США, например,
существуют различные
консультационные фирмы, которые
периодически оценивают и публикуют
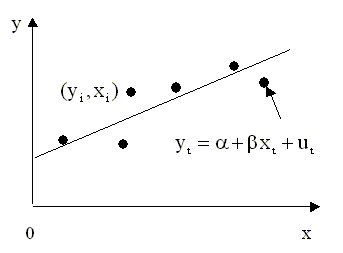
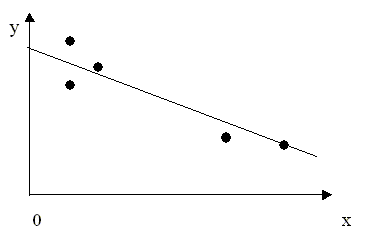
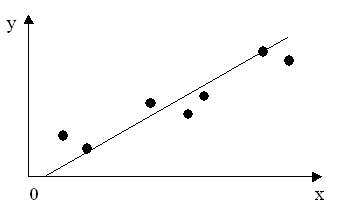
обновленные оценки коэффициентов Многофакторные модели доходности ценных бумаг Привлекательной чертой рассмотренной выше однофакторной модели является ее простота. Основным же ее недостатком является возможность недостаточно адекватного описания процесса ценообразования. Более точно процессы формирования доходностей ценных бумаг можно описать с помощью многофакторных моделей, которые относятся к классу моделей множественной линейной регрессии. Состояние экономики зависит от многих факторов, среди которых можно выделить несколько основных, оказывающих влияние на все сферы экономики: 1. темпы прироста валового внутреннего продукта 2. уровень инфляции 3. уровень процентных ставок 4. уровень цен на нефть Учет этих и других факторов - экзогенных, независимых переменных, позволяет построить более совершенные модели доходности ценных бумаг. Ярким примером успешного создания и применения многофакторных моделей на практике является широко известная модель BARRA для ценных бумаг США (эта модель описана в книге У.Ф. Шарп и др. Инвестиции. М.: ИНФРА - М. 1997,[34]). Один из ее создателей, Барра Розенберг, основал консалтинговую фирму BARRA с целью совершенствования модели и продажи полученных на ее основе прогнозов институциональным инвесторам. Фирма успешно развивается и приносит ежегодный доход, превышающий $40 млн. Размер ее рыночной капитализации превышает $50 млн. Со временем модель претерпела существенные изменения и в настоящее время она называется моделью E2. 630 институциональных инвесторов в США и за их пределами являются подписчиками службы этой модели. Общая стоимость активов, которыми они управляют на фондовом рынке США, более чем $1 трлн. Крайне поучительным является процесс создания модели E2, описание которого дано в книге [34]. Первый этап построения модели состоял в сборе информации о ценных бумагах. Она включала данные о ценах, дивидендах, объеме размещенного капитала для обыкновенных акций 1400 компаний за длительный период времени. Кроме того, использовались финансовые данные из годовых и квартальных финансовых отчетов компаний. Важным, критическим шагом в построении модели, была проверка качества собранных данных, поскольку даже небольшое количество недостоверной информации может существенно отразиться на качестве модели. На втором этапе были отобраны наиболее существенные факторы, влияющие на доходности и риски ценных бумаг. Среди сотен потенциальных претендентов на включение в модель, на основе прошлых данных, BARRA определила 70 факторов, влияющих на курсы ценных бумаг. Совокупность факторов, в частности, включала такие как коэффициент "бета" для акции за прошедший период, прогноз роста ее доходов, изменчивость ее доходов в прошлом, отношение долгов к активам, число аналитиков по ценным бумагам, использующих данные по ее акциям, доля операционных доходов компании, полученных за счет зарубежных источников. Затем, на третьем этапе создания модели эти 70 первоначально выделенных факторов были преобразованы в 13 составных факторов, характеризующих изменчивость рынков, торговую активность, рост, отношение дохода к цене, интенсивность труда, вариацию доходов и др. Помимо этих 13 фундаментальных факторов, в модель были включены еще 55 промышленных факторов, характеризующих отдельные отрасли. Таким образом, модель E2, разработанная фирмой BARRA, содержит 68 экзогенных переменных (факторов). На четвертом этапе на базе модели производилась оценка доходностей по каждому из 68 факторов в пределах пробного временного интервала. На пятом этапе была проведена оценка качества построенной модели. При этом проверялось, насколько точны прогнозы, полученные с помощью модели, за пределами пробного интервала. Результаты проверки подтвердили хорошую работу модели. Модель находит разнообразные применения на практике. Финансовые менеджеры используют модель для прогнозов изменчивости в доходности их портфелей ценных бумаг. С помощью модели менеджеры определяют степень влияния каждого фактора на доходность их портфеля за отчетный период и вклад каждого из факторов в полную доходность портфеля. Институциональные инвесторы используют модель для оценки эффективности работы и инвестиционного стиля их менеджеров. Многофакторная модель BARRA для ценных бумаг США получила широкое признание и "оказала влияние на строгость и сложность, с которой институциональные инвесторы подходят к задаче управления большими пакетами обыкновенных акций в США" (У.Шарп, 1997). 2.1.4. Основные формально-математические проблемы, возникающие при построении регрессионных моделей. Роль информационного обеспечения моделей После того, как модель специфицирована (т.е. определен вид функциональной зависимости между переменными) для полного построения регрессионной модели необходимо решить следующие, по-существу математико - статистические, проблемы: 1. оценить параметры модели по имеющимся наблюдаемым данным зависимой и независимых переменных; 2. провести статистический анализ полученных оценок, изучить их свойства, установить степень их надежности; 3. провести статистический анализ модели в целом и таким образом установить степень адекватности построенной модели имеющимся статистическим данным или, другими словами, оценить уровень доверия к построенной модели; 4. оценить прогнозные возможности модели, степень надежности и достоверности прогнозов, т.е. насколько правильно модель объясняет поведение изучаемого объекта. Без решения вышеперечисленных проблем задача построения модели не может считаться полностью завершенной. Для решения каждой из них в эконометрической теории в настоящее время разработано множество различных методов и подходов, основные из которых и являются предметом изучения в дальнейшем. Здесь же заострим внимание на роли информационного обеспечения моделей. Необходимо четко представлять, что никакие, даже самые изощренные математические методы, не заменят достоверной, постоянно обновляемой статистической информации об изучаемом объекте или процессе. Полноценное информационное наполнение модели - основа успеха при эконометрическом моделировании. Нельзя получать достоверные выводы, основываясь на недостоверной информации. Поэтому сбор и оценка качества статистических данных являются, возможно, самыми важными этапами построения эконометрической модели. Необходимо также хорошо представлять, насколько достоверными являются имеющиеся данные, и если нельзя получить другие, более качественные данные, скажем, из-за высокой стоимости дополнительных статистических исследований, или недоступности качественной информации, необходимо правильно оценить принципиальную возможность построения адекватной модели на основе таких данных, в том числе используя формально-математические методы. Необходимо хорошо представлять границы применимости таких моделей. Именно для понимания и правильного решения этих проблем необходимо глубокое изучение курса "Эконометрика". Специалист, владеющий эконометрическими методами, имеет преимущество и на рынке труда и при ведении собственного бизнеса. 2.1.5. Модель парной линейной регрессии Более глубокое изучение регрессионных моделей начнем с модели парной линейной регрессии. Эта модель является частным случаем модели многомерной регрессии, но ее изучение представляет самостоятельный интерес, поскольку она имеет многие характерные свойства общих многомерных моделей, но более наглядна и проста для изучения. Парная линейная регрессионная модель используется для описания линейной функциональной взаимосвязи двух переменных, если исходя из анализа объекта исследования предполагается, что такая связь объективно существует. Вывод о предполагаемой линейной зависимости можно сделать, построив так называемую диаграмму рассеяния, на которой в плоскости (y,x) графически отображаются точки с координатами (yi, xi), i=1,2...,n, соответствующие наблюдаемым значениям переменных. Примеры диаграмм рассеяния приведены на рис. 2.1а, 2.1б, 2.1в. По виду этих диаграмм можно сделать предположение, что между переменными y и x возможно существует приближенная линейная зависимость. Замечание. Следует иметь ввиду, что предположение о наличии линейной связи основано лишь на ограниченном фиксированном числе наблюдений, которыми располагает аналитик. Возможно, что если бы наблюдений было больше, то это позволило сделать предположение о некоторой, отличной от линейной, закономерности. Диаграммы рассеяния, по виду которых можно предположить существование линейной зависимости Модель парной линейной регрессии, которая выражает линейную зависимость в математической форме, обычно записывается в виде
Заметим, что в этой записи для
обозначения параметра сдвига
используется символ 1. С помощью случайной составляющей учитывается влияние на зависимую переменную некоторых, не учитываемых явно в модели, случайных факторов. Происхождение этих факторов может быть различным. Возможно, что исследователь сознательно не включает известные ему факторы в модель, во-первых, в силу их большого количества и, во-вторых, считая их влияние нерегулярным и не существенным по сравнению с влиянием независимой переменной. Тогда учет этих факторов осуществляется с помощью случайной составляющей. Возможно, что исследователь не знает, какие скрытые (латентные) факторы влияют на зависимую переменную, но подозревает об их существовании, поскольку из анализа наблюдаемых данных можно сделать вывод о том, что линейная зависимость между переменными y и x получается лишь приближенно. 2. С помощью введения случайной составляющей учитывают ошибки, которые могут присутствовать в наблюдениях зависимой переменной y. 3. С помощью случайной составляющей в определенной степени можно учесть неточность (ошибки) спецификации модели. Как бы то ни было, но при построении количественных моделей реальных социально-экономических процессов по эмпирическим данным невозможно явно учесть все факторы, которые могут оказывать влияние на зависимую переменную, эти факторы так или иначе себя проявляют, причем, как правило, нельзя отделить влияние одних факторов от других, все они действуют в совокупности. Поэтому оценка роли случайной составляющей и анализ ее характеристик является важнейшим этапом эконометрического моделирования.
|